Following the identification phase of the incident handling process, where among others you have identified malicious acts or deviations from the normal operation. It comes the containment phase. During the containment phase you want to stop the damage. Stop the bleeding and pause the attacker in the most quick and effective manner without changing evidence and using a low profile approach. There isn’t a silver bullet on how to do containment because every case is unique however there are some strategies that you can use. Some examples of short term containment include disconnecting the network cable, redirecting the impacted system DNS name to another IP address, creating a firewall rule or if your infrastructure allows put the system into a separated isolated vlan. During this process engage the business owners and decide the best approach. Do not gracefully shutdown the system because it will destroy important evidence, artifacts and you will lose all your volatile data.
Following the identification phase of the incident handling process, where among others you have identified malicious acts or deviations from the normal operation. It comes the containment phase. During the containment phase you want to stop the damage. Stop the bleeding and pause the attacker in the most quick and effective manner without changing evidence and using a low profile approach. There isn’t a silver bullet on how to do containment because every case is unique however there are some strategies that you can use. Some examples of short term containment include disconnecting the network cable, redirecting the impacted system DNS name to another IP address, creating a firewall rule or if your infrastructure allows put the system into a separated isolated vlan. During this process engage the business owners and decide the best approach. Do not gracefully shutdown the system because it will destroy important evidence, artifacts and you will lose all your volatile data.
There are times that the incident handler is also gathering evidence to deliver to the forensics team or the incident handler also does the forensics analysis. Depending on the case you might be working, you might see an overlap between incident handling and forensics but the processes and procedures go hand in hand. From a forensics perspective do a forensics image of the affected system. This means gathering the file system using a disk imaging process and a memory dump (volatile data). You should start by gathering the volatile data, then you do a disk image. With these elements you can do a thoroughly analysis of the data. During the forensics data analysis, among other things, you will look at the file system at bit level, analyzing several artifacts such as program execution, files download, file opening and creation, usb and drive usage, account usage, browser usage, etc.
Create a forensic image of the disk as soon as is practical. Make sure you use blank media in a pristine state to create a copy of the impacted system. This blank media e.g, usb hard drive, should be wiped. You clean and prepare the drive during the preparation phase. You do not want to be wiping drives while going under fire! To do the disk image you should do a bit-by-bit image using your preferred toolkit. Don’t use the tools from the compromised system because you cannot trust them. Use binaries from a another source. One example is the linux based toolkit Helix that brings the dd tool built in that will assist you doing the forensic image of the hard drive – Helix product went commercial but you can still download the free 2009R3 version – . Once you created the image and ensure its integrity, is good practice to record the time and the evidence creation method including the image hash on your incident handler notebook. If times allow create more than one image. Most of the times you don’t have time because a image creation can take several hours to execute. In such case you do a duplicate offsite and then you do your analysis using the duplicate. Image creation is a simple task but you need to practice it.
To do the image creation of the hard drives the traditional way is to remove the hard drive from the impacted system and create a forensic image using a write block. But other times this method is not practical. Another way of making a forensic image of the hard drive is to use live acquisition methods, boot disk acquisition or using remote/enterprise grade tools. A live system acquisition might be useful in cases the affected drive is encrypted or you have a RAID across multiple drives or is not feasible to power down the machine. However, this method will only grab the logical part of the hard drive i.e. partitions such as FAT, NTFS, EXT2, etc.
The other method is using a bootable forensic distro such as Helix. You need to reboot the system and boot the system using CD/USB. This allows to create a bit-by-bit image of the physical drive, the evidence on the drive is not altered during boot process and you can create an image of the hard drive into a image file. This image file can then be used across different analysis tools and is easier to backup.
Let’s look at an hands-on scenario to create a forensic image using a bootable disk method from a compromised or suspicious system using dd. Dd is simple and flexible tool that is launched using the command line and is available for Windows and Linux. In this case we will run dd in a Linux system. What dd does is only copying chunks of raw data from one input source to an output destination. It does not know nothing about partitions or file systems. dd reads from its input source into blocks (512 bytes of data by default) specified by the if= suffix. It then writes the data to an output destination using the of= suffix.
We start by using dd to prepare a target hard drive. We will wipe the data of an hard drive that we will be using to gather the evidence. We will use dd to zeroize an 320Gb USB drive. This will render the drive sterile and into a pristine state. Plug the USB drive into a Linux system and execute fdisk -lu to display available drives on the system. In this case we have 2 drives. One is the /dev/sda which is the internal hard drive of the system and the /dev/sdb which is the 320Gb drive that we plugged into the system. The /dev/sdb does not contain any valid partitions and this is ok for now because we only want to wipe it.
root@ubuntu:~# fdisk -lu
Disk /dev/sda: 160.0 GB, 160041885696 bytes
255 heads, 63 sectors/track, 19457 cylinders, total 312581808 sectors
Units = sectors of 1 * 512 = 512 bytes
Disk identifier: 0x0006784f
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 206847 102400 7 HPFS/NTFS
Partition 1 does not end on cylinder boundary.
/dev/sda2 206848 312578047 156185600 7 HPFS/NTFS
Disk /dev/sdb: 320.0 GB, 320072933376 bytes
255 heads, 63 sectors/track, 38913 cylinders, total 625142448 sectors
Units = sectors of 1 * 512 = 512 bytes
Disk identifier: 0x00000000
Disk /dev/sdb doesn't contain a valid partition table
Next execute dd specifying as input the special file /dev/zero and the /dev/sdb as the output drive by using a block size of 8k to increase the speed of the process. This will create zeros across the entire drive. Be careful with this command and make sure you are wiping the right drive. On our system this process took more than 3 hours to complete.
root@ubuntu:~# dd if=/dev/zero of=/dev/sdb bs=8k
dd: writing `/dev/sdb': No space left on device
39071404+0 records in
39071403+0 records out
320072933376 bytes (320 GB) copied, 11579.9 s, 27.6 MB/s
The “No space left on device” error is normal. Also note that the number of records in and out multiplied by the block size (8192) will get you the number of bytes copied.
To confirm that the drive has been zeroized you can dump the contents using xxd.
root@ubuntu:~# cat /dev/sdb | xxd | more
0000000: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
We have now prepared our media for the acquisition process. Now that we have pristine media we can do our forensic image. Boot the Helix CD on the target/compromised system and plug the USB media. Then create a EXT2 file system using fdisk and mke2fs.
root@ubuntu:~# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0x7b441f7a.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
The number of cylinders for this disk is set to 38913.
There is nothing wrong with that, but this is larger than 1024,
and could in certain setups cause problems with:
1) software that runs at boot time (e.g., old versions of LILO)
2) booting and partitioning software from other OSs
(e.g., DOS FDISK, OS/2 FDISK)
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
Command (m for help): m
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
Command (m for help): p
Disk /dev/sdb: 320.0 GB, 320072933376 bytes
255 heads, 63 sectors/track, 38913 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Disk identifier: 0x7b441f7a
Device Boot Start End Blocks Id System
Command (m for help): n
Command action
e extended
p primary partition (1-4) p
Partition number (1-4): 1
First cylinder (1-38913, default 1):
Using default value 1
Last cylinder or +size or +sizeM or +sizeK (1-38913, default 38913):
Using default value 38913
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
root@ubuntu:~# mke2fs /dev/sdb1
mke2fs 1.40.8 (13-Mar-2008)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
19537920 inodes, 78142160 blocks
3907108 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=0
2385 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 25 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
root@ubuntu:~# fdisk -lu
Disk /dev/sda: 160.0 GB, 160041885696 bytes
255 heads, 63 sectors/track, 19457 cylinders, total 312581808 sectors
Units = sectors of 1 * 512 = 512 bytes
Disk identifier: 0x0006784f
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 206847 102400 7 HPFS/NTFS
Partition 1 does not end on cylinder boundary.
/dev/sda2 206848 312578047 156185600 7 HPFS/NTFS
Disk /dev/sdb: 320.0 GB, 320072933376 bytes
255 heads, 63 sectors/track, 38913 cylinders, total 625142448 sectors
Units = sectors of 1 * 512 = 512 bytes
Disk identifier: 0x7b441f7a
Device Boot Start End Blocks Id System
/dev/sdb1 63 625137344 312568641 83 Linux
The fdisk created a partition that used the entire disk and the mk2fs created the file system (note the command run on /dev/sdb1). Finally with the fdisk -lu you could confirm that the partition was formated using with an EXT2. The next step is mount the file system by creating a mount point and then mounting the partition.
root@ubuntu:~# mkdir /mnt/target
root@ubuntu:~# mount /dev/sdb1 /mnt/target
Then we are ready to start our bit-by-bit image creation. This method will gather the allocated space, unallocated space and slack space, bad blocks. This means will grab the all the sectors from the hard drive from the MBR to the final sector including the Host Protected Area (HPA) if it exists.
Start by creating a cryptographic fingerprint of the original disk using MD5. This will be used to verify the integrity of the duplicate. Then using dd with the input source being the /dev/sda and the output file a file named suspect.img. Other usefull options is the conv=sync,noerror to avoid stopping the image creation when founding an unreadable sector. If such sector is found with this option, it will skip over the unreadable section (noerror) and pad the output (sync). Finally create the fingerprint of the image created and verify that both fingerprints match and unmount the drive.
root@ubuntu:~# md5sum /dev/sda > /mnt/target/suspect.md5
root@ubuntu:~#dd if=/dev/sda of=/mnt/target/suspect.img conv=sync,noerror bs=8k
19536363+0 records in
19536363+0 records out
160041885696 bytes (160 GB) copied, 5669.92 s, 28.2 MB/s
root@ubuntu:~#md5sum /mnt/target/suspect.img > /mnt/target/suspect.img.md5
root@ubuntu:~# cat /mnt/target/*.md5
6a5346b9425925ed230e32c9a0b510f7 /mnt/target/suspect.img
6a5346b9425925ed230e32c9a0b510f7 /dev/sda
root@ubuntu:~# umount /mnt/target/
The creation of the image is a simple process but you should practice it. Under fire is much harder to accomplish these type of activity. Also it is a process that can take several hours to accomplish. In our case took around 90m. The integrity checking took around the same time. With these steps we created a forensically sound image of an hard drive in a bit-by-bit manner and we ensured its integrity.
Now that we collected a forensic image we could start our forensics investigation by doing an in-depth analysis of the file system and analyzing several artifacts such as program execution, files download, file opening and creation, usb and drive usage, account usage, browser usage, etc. To do this we could use the SANS Investigative Forensic Toolkit (SIFT) and start practicing tools and techniques to discover evidence and tracks about the suspect. During our investigation we might want to gather data to answer questions such as:
How did the attacker gain entry?
What is the latest evidence of attacker activity?
What actions did the attacker execute on the system?
How did the attacker maintained access to the environment?
What tools has the attacker deployed?
What accounts did the attacker compromise?
References:
SANS Forensics 508 – Advanced Computer Forensic Analysis and Incident Response

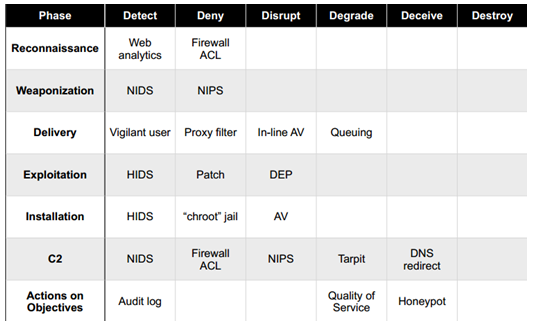
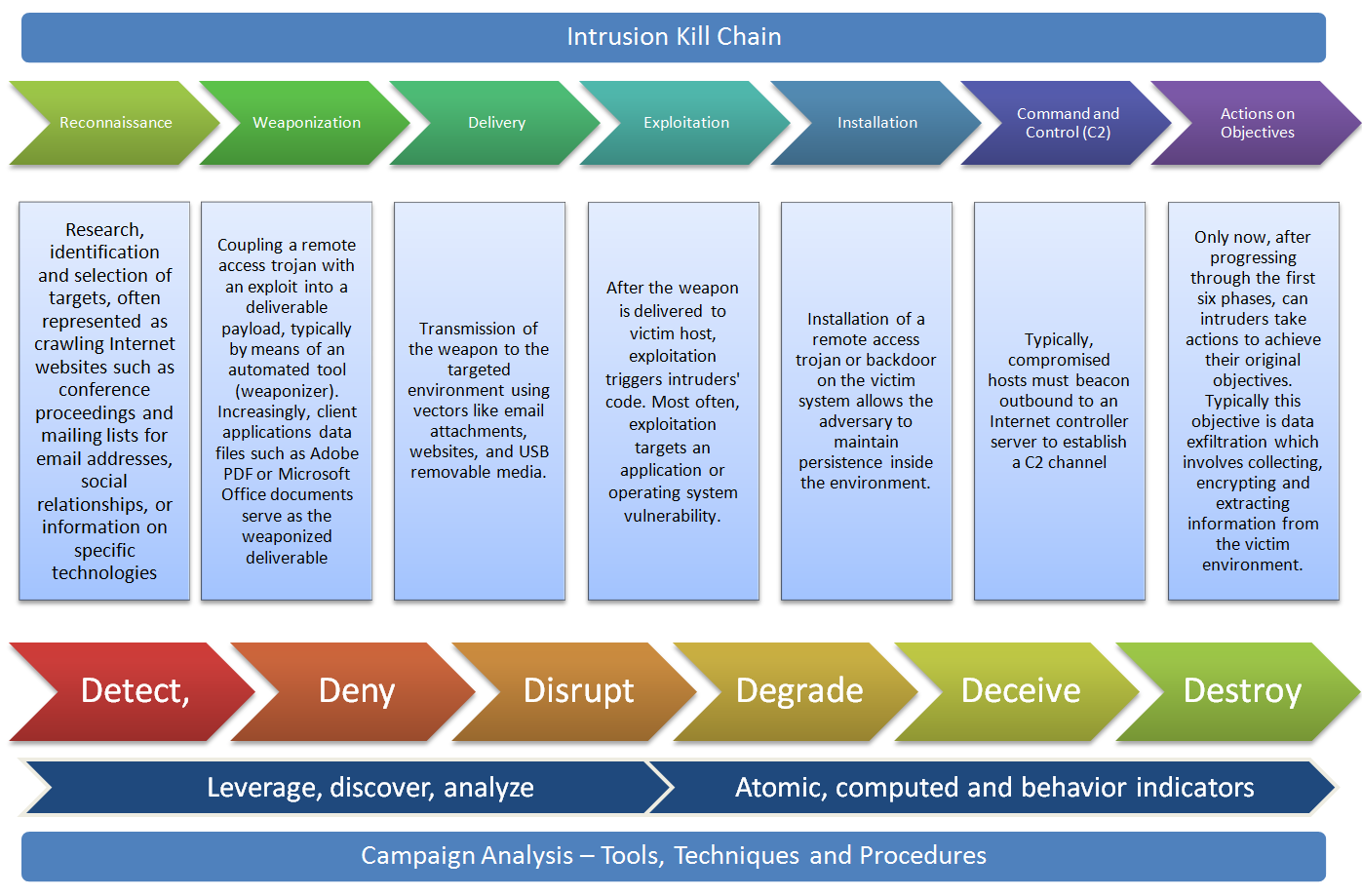 Back in March 2011, Eric Hutchins, Michael Cloppert and Dr. Rohan Amin from Lockheed Martin (US Gov defense contractor) released a paper named Intelligence Driven Computer Network Defense Informed by Analysis of Adversary Campaigns and Intrusion Kill Chains. This was a great contribution to the IT security community because it describes a novel way to deal with intrusions. They claim that current tools and models that deal with intrusions need to evolve mainly due to two things. First network defense tools focus on the vulnerability component of the risk instead of the threat. Second the traditional way of doing incident response happens after a successful intrusion. To solve this problem they propose a model that leverages an understanding about the tools and techniques used by the attackers creating intelligence that is then used to decrease the likelihood success of an intrusion. In order to understanding the threat actors , their tools and techniques they adopted models and terms that have origins in the US military. Essentially they propose to maps the steps taken by attackers during an intrusion. These steps are then intersected with a chain of events with the goal to detect, mitigate and respond to intrusions based on the knowledge of the threat using indicators, patterns and behaviors that are conducted during the course of action of the intrusion.
Back in March 2011, Eric Hutchins, Michael Cloppert and Dr. Rohan Amin from Lockheed Martin (US Gov defense contractor) released a paper named Intelligence Driven Computer Network Defense Informed by Analysis of Adversary Campaigns and Intrusion Kill Chains. This was a great contribution to the IT security community because it describes a novel way to deal with intrusions. They claim that current tools and models that deal with intrusions need to evolve mainly due to two things. First network defense tools focus on the vulnerability component of the risk instead of the threat. Second the traditional way of doing incident response happens after a successful intrusion. To solve this problem they propose a model that leverages an understanding about the tools and techniques used by the attackers creating intelligence that is then used to decrease the likelihood success of an intrusion. In order to understanding the threat actors , their tools and techniques they adopted models and terms that have origins in the US military. Essentially they propose to maps the steps taken by attackers during an intrusion. These steps are then intersected with a chain of events with the goal to detect, mitigate and respond to intrusions based on the knowledge of the threat using indicators, patterns and behaviors that are conducted during the course of action of the intrusion.