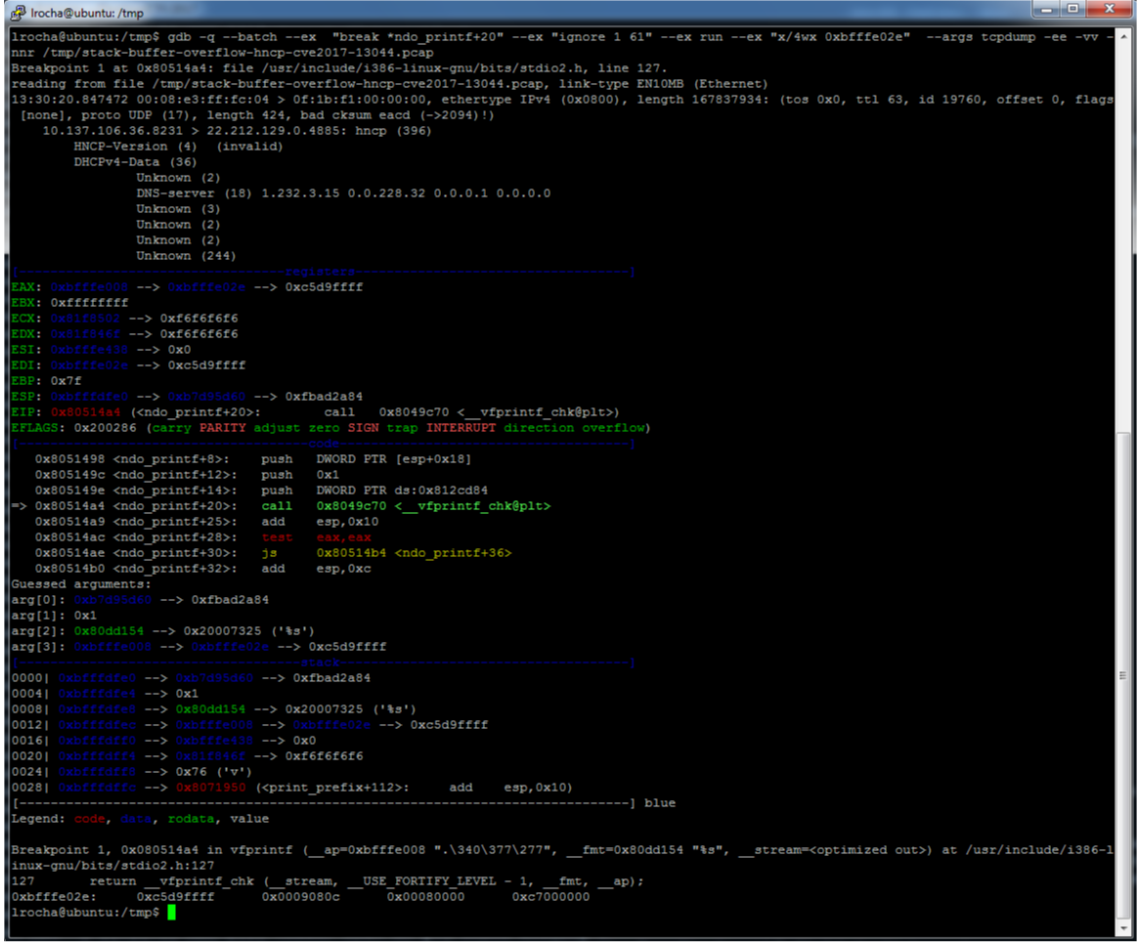
Today I am going to write a few notes about tools that should be part of your toolkit in case you use FireEye Endpoint Security product a.k.a. as HX. If you don’t use FireEye HX, this post likely has no interest for you.
I tend to use HX when performing large scale Enterprise Forensics and Incident Response. I also tend to see HX or other EDR solutions on organizations with mature security operations that use such technology to increase endpoint visibility and improve their capabilities to detect and respond to threats on the endpoints. HX is very powerful, feature rich but like many EDR products it tends to be designed for more seasoned incident responders with specialized skill set. HX can be used in the realm of protection, detection, and response. Today’s notes are primarily focused on two things: Increase awareness about tools that will help augment HX capability to detect attacks; Increase awareness about tools that will help the analyst ability to work with the results. Goal is to improve threat detection and ability to analyze the results therefore increase the effectiveness of your product and maximize the outcome of your investigations.
FireEye makes available a website named fireeye.market where one can download apps that extend the functionality of existing products. If you are a FireEye customer you likely have seen this before. For this post I’m looking at the Endpoint Security apps that might extend the functionality of the HX or enhance the analyst ability to perform the work faster/better. On the FireEye Market website there are a few things that are freeware and can be downloaded without subscription. Others may require a subscription. One of the main freeware tools is the IOC Editor. Let’s briefly go over some of the things that will be useful.
Indicators of Compromise (IOC) Editor is a free tool for Windows that provides an interface for managing data and manipulating the logical structures of IOCs. IOCs are XML documents that help incident responders capture diverse information about threats, including attributes of malicious files, characteristics of registry changes, artifacts in memory, etc. There are two versions of IOC editor in the website. We want the IOC 1.1 editor version 3.2. The installation file Mandiant IOCe.msi can be downloaded from here https://fireeye.market/apps/211404 . The archive is IOCe-3.2.0-Signed.msi.zip (3EE56F400B4D8F7E53858359EDA9487C). This version brings updated IOC terms that allow us to create IOCs for HX real-time alerting and for searching the contents of the HX event buffer (ring buffer). Note that Redline does not support IOC 1.1. If you are a developer or interested in the details IOC 1.1 specification you can look here https://github.com/mandiant/OpenIOC_1.1. This schema is what Mandiant services uses internally to extend functionality of IOC Editor and support new and extended terms. The IOC editor contains two main set of terms: On one hand you have the terms that can be used to search for historical artefacts (Sweep) and on the other hand you have the terms that can be used to search event buffer (Real-Time) or generate real time alerts. All terms are created with a set of conditions and logic needed to describe and codify the forensic artefacts.
OpenIOC2HXIOC
When you use IOC editor to create, edit, maintain your Real-Time IOCs you need to upload them to HX either for testing or to be on released on production. One way to accomplish this is to use the Python script that takes IOCs as input and uploads them into HX to be used on Real Time alerting. This script can be downloaded from https://fireeye.market/apps/213060. You will need Python and a HX user account with API rights because the script takes advantage of the HX API to perform the work.
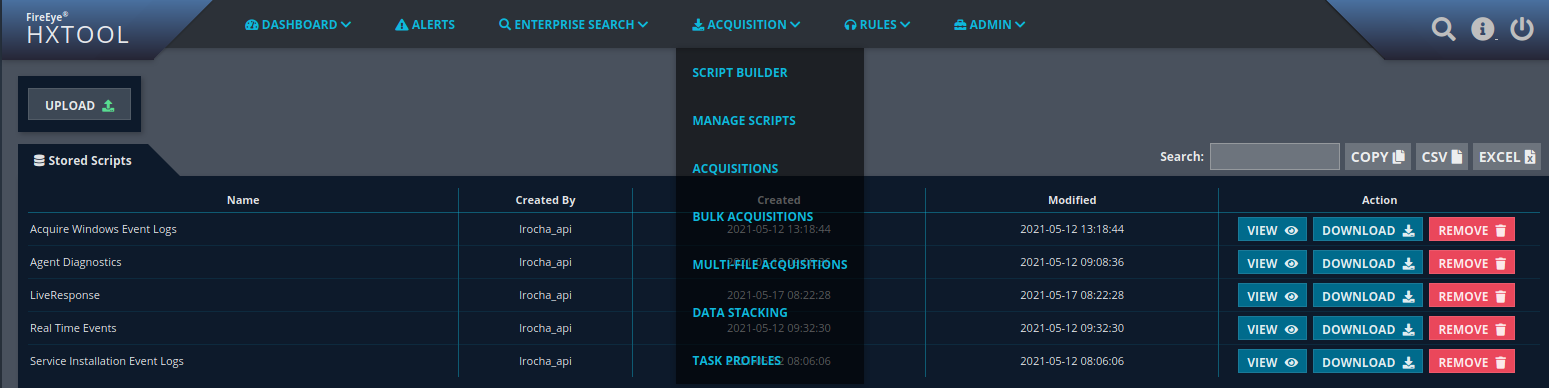
HXTOOL
HXTool, originally created by Henrik Olsson in 2016, is a web-based, opensource, standalone tool written in python. that can be used with HX. HXTool provides additional features not directly available in the product GUI by leveraging FireEye Endpoint Security’s rich API. Since the code now is open source, this tool is an excellent example of how you can develop applications utilizing the Endpoint Security REST API. It is available in FireEye’s public GitHub at https://github.com/fireeye/HXTool.
After installation, open a webbrowser and point it to localhost on port 8080. In the HXTool create a new profile with the IP address and port of the HX controller. Then connect with a user that has API Admin rights and was previously created in the HX management interface. There are many features in HX tool but the ability to use Script Builder to create audit scripts allows you fully leverage the potential of HX. After you create a script you run Sweeps using the bulk-acquisition method. The Sweeps can be used to perform enterprise forensics at scale or to look for real time data stored in the ring buffer of the endpoints. Nonetheless, you can use HXTool to perform stack analysis, enterprise searches based on OpenIOC 1.1, create, and maintain the Real-Time indicators, etc.
$ git clone https://github.com/fireeye/HXTool Cloning into 'HXTool'... remote: Enumerating objects: 6401, done. remote: Counting objects: 100% (90/90), done. remote: Compressing objects: 100% (70/70), done. remote: Total 6401 (delta 39), reused 55 (delta 20), pack-reused 6311 Receiving objects: 100% (6401/6401), 14.64 MiB | 5.08 MiB/s, done. Resolving deltas: 100% (4337/4337), done. $cd HXTool/ $ pip install -r requirements.txt --user(..) Installing collected packages: itsdangerous, MarkupSafe, Jinja2, click, Werkzeug, flask, pycryptodome, tinydb, six, python-dateutil, numpy, pytz, pandas Successfully installed Jinja2-2.11.2 MarkupSafe-1.1.1 Werkzeug-1.0.1 click-7.1.2 flask-1.1.2 itsdangerous-1.1.0 numpy-1.16.6 pandas-0.24.2 pycryptodome-3.9.7 python-dateutil-2.8.1 pytz-2020.1 six-1.15.0 tinydb-3.15.2 $ python3 hxtool.py (..) [2020-06-02 01:39:41,497] {hxtool} {MainThread} INFO - Application starting[2020-06-02 01:39:41,501] {hxtool} {MainThread} INFO - Application is running. Please point your browser to https://0.0.0.0:8080. Press Ctrl+C/Ctrl+Break to exit. * Serving Flask app "hxtool" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off |
Supplementary IOCs
In the FireEye market website, there are a set of FireEye released Real-Time IOCs designed to supplement FireEye Endpoint Security’s production indicators. They were created for environment-specific detection and testing, like tests based on MITRE’s ATT&CK framework. Most of these IOCs will require substantial tuning to use in a production environment. They need to be customized for your environment and should not be uploaded in bulk. This set contains more than 400 IOCs and can be obtained from https://fireeye.market/apps/234563
FireEye Red Team IOCs. Last December as result of an incident, FireEye released a set of IOCs to detect FireEye Red Team tools. These IOCs empower the community to detect these tools and are available in different formats including OpenIOC, Yara, Snort, and ClamAV. There are more than 80 IOCs in OpenIOC format and can be downloaded from https://github.com/fireeye/red_team_tool_countermeasures
The first set of IOCs are very broad and need to be customized for a particular environment but they offer a starting point for security teams to test and get familiar with the process. The lifecycle of designing, building, deploying, and adopting IOCs is part of the Security monitoring and/or Incident Response capability where well trained and well equipped personnel alongside with consistent and well defined process come into play. If you want to be able to run sophisticated threat hunting missions you first should be able to understand the threat, understand the indicators that help you identify the threat in your network and then you can create and maintain IOCs that may represent that threat. The second set of IOCs are overall very good but some of them need tunning specially the LOLBINs and the suspicious DLL executions.
GOAUDITPARSER
So, by now, with the things that were covered, you have a set of IOCs that you uploaded to HX using the OpenIOC2HXIOC script and you used the HXTool to Sweep your environment to look for threats or you used them to generate Real-Time alerts. But how to analyze the results? Traditionally you likely used the HX GUI or downloaded the data and used Redline. However, we can now use some other technique. Daniel Pany just recently open sourced GoAuditParser. A versatile and customizable tool to help analysts work with FireEye Endpoint Security product (HX) to extract, parse and timeline XML audit data. People have used Redline to parse and create a timeline of the data acquired with HX but using this tool an analyst may be able to improve his ability to perform analysis on the data at scale obtained via HX. The compiled builds of the tool can be downloaded from https://github.com/fireeye/goauditparser/releases/tag/v1.0.0. Danny has published extensive documentation on how to use the tool on GitHub.

That’s it for today. If you use HX you can now improve your investigation methods using the mentioned tools. Consider and think about the following 3 steps:
- Based on leads or alerts you collect Live Response data
- Use HXTool Script Builder to create a script to acquire Live Response Data
- Use HXTool to run a Bulk Acquisition to run the acquisitions of Live Response data
- Download the Live Response Acquisition using HXTool
- Analyze results & develop timeline
- Use GoAuditParser to extract, parse and timeline the results.
- Perform the forensic investigation by interpreting the results
- Use your favorite tool to create a timeline (likely Excel)
- Design, build, deploy and adopt Real-Time IOCs and Sweep IOCs
- Use IOC editor to build IOCs that represent your findings
- Use IOC editor to create IOCs for both Sweeps and Real-Time
- Deploy Real-Time IOCs using OpenIOC2HXIOC
- Create Sweeps with HXTool using Script Builder, Job Filters in conjunction with IOCs to filter results and BulkAcquistions.
- Repeat
Hopefully this short summary increases the awareness on how to use HX more efficiently. It also serves to capture a perspective on how to use HX because you can use such tools to handle real security incidents and intrusions at enterprise level.
References:
Endpoint Security Server User Guide Release 5.0.2
Endpoint Security Server System Administration Guide Release 5.0.2
IOC Editor 2.2.0.0 User Guide